Masking in Mule 4| In this tutorial will see how we can mask or encrypt json / xml fields in Mule 4, while printing logs or hiding PII data.
Mule too have an inbuild mask function to support masking (Link), but it has couple of drawbacks.
- With mule mask function you can mask only 1 field at a time. For masking multiple fields, you need to write same function multiple times, which makes it useless in most of the scenarios.
- With this mule mask function, you can mask / encrypt the field value, but then you won’t be able to get the original value back.
With the given tutorial you would be able to overcome both the above problems by writing simple dataweave script.
%dw 2.0
fun mask(content, y) =
if(typeOf(content) ~= "Object")
(content mapObject (value, key) -> {(
if((y contains ((key) as String)) and (typeOf(value) ~= 'String' or typeOf(value) ~= 'Boolean' or typeOf(value) ~= 'Number'))
((key): mask( ("*****"),y) )
else
((key): mask(value,y))
)})
else if(typeOf(content) ~= "Array")
(content map mask($,y))
else
content
In the above dataweave script, function excepts 2 input param:
- content -> Payload (JSON/XML)
- Y -> Fields needed to be encrypted (Array)
How above masking script works:-
This function checks the payload type
- If its Object, then loop through each field in that object and mask/encrypt fields that matches with field name defined in 2nd param Y and fields that are String, Boolean or Number.
- If its an Array then loop further inside array using same calling function.
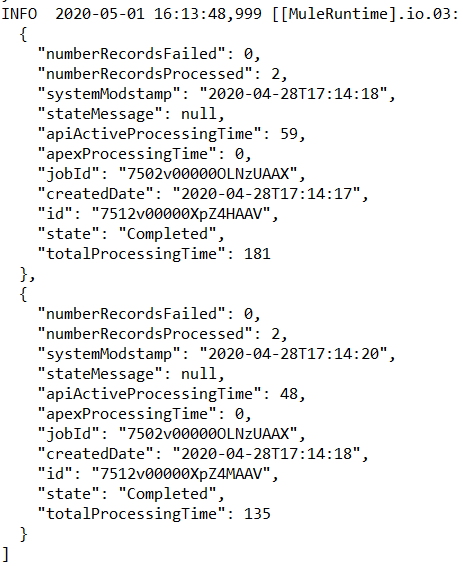
Below is the screenshot of the script in action:

There might be chance, where you would need to use masking script to encrypt various fields again and again in various dataweave transformation or while logging. Rather than writing whole script again; one of best way is to create an importable dataweave class that can be externalized and used easily in every transformation needed in a single line.
You can do this be creating below dwl file in “src/main/resources/modules/” Mule project.
DWL filename – “maskFields.dwl”
%dw 2.0
var maskKeyValue = (function, x = [], y = []) -> function (x, read(y default "[]","application/json"))
fun mask(content, y) =
if(typeOf(content) ~= "Object")
(content mapObject (value, key) -> {(
if((y contains ((key) as String)) and (typeOf(value) ~= 'String' or typeOf(value) ~= 'Boolean' or typeOf(value) ~= 'Number'))
((key): mask( ("*****"),y) )
else
((key): mask(value,y))
)})
else if(typeOf(content) ~= "Array")
(content map mask($,y))
else
content
And now in your xml code you can call this dwl as below –
%dw 2.0 import modules::maskJsonField output application/json --- maskFields::maskKeyValue(maskFields::mask, payload, ["name","age","street"])
or
Using prop file storing fields to be mask.
%dw 2.0
import modules::maskJsonField
output application/json
---
maskFields::maskKeyValue(maskFields::mask, payload, Mule::p("fieldsToMask") default "[]")
dev.yml (property file) –
fieldsToMask : “[\”NAME\”, \”age\”, \”street\”]“